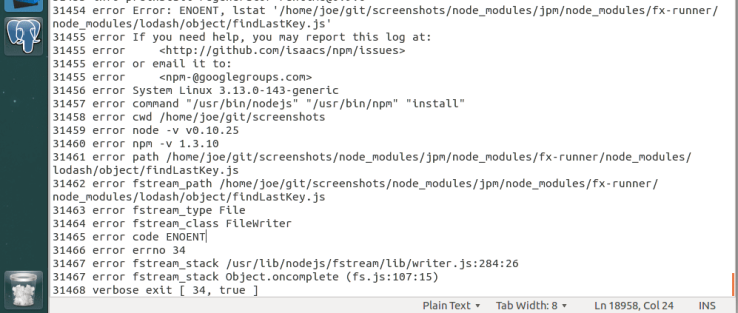
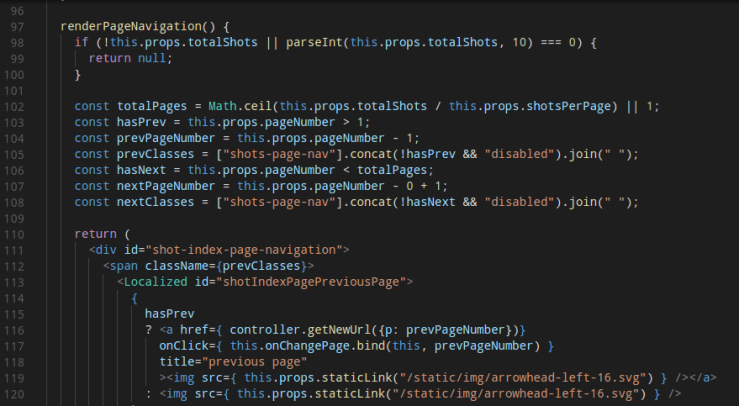
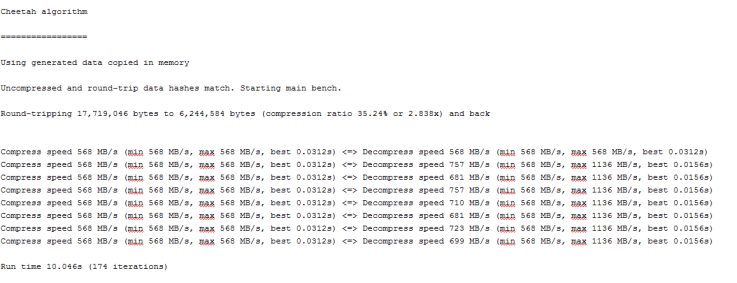
For the final release, I decided to stick with Firefox Screenshots. I was still having issues with debugging the extension, so this time I took a different approach. I looked through the solved/closed issues to see if there was any mention of debugging or something that could possibly help me. I stumbled upon a closed issue that used Firefox Nightly to recreate the issue. Maybe if I tried recreating bugs with solved issues, it will help me with my debugging issue. I felt like I was getting closer to being able to debug the extension, but again, no luck. With all of these problems and no help from their documentation, I decided that I should document how to install the extension for Linux.
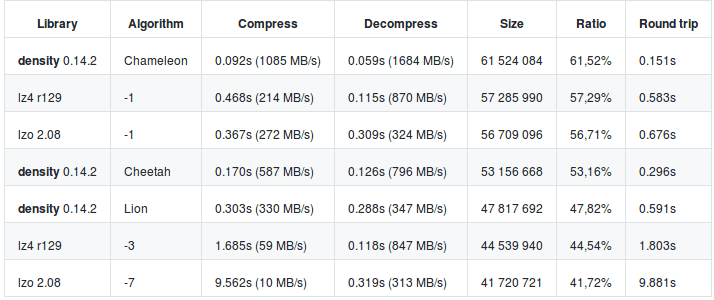
I remember when I first started on this project, it took me about 4 hours to install PostgreSQL and to get the server up and running. Now that I am familiar with PostgreSQL, it took me about 10 mins to uninstall, purge and reinstall it. The installation isn’t too difficult if you know what you are doing. I uninstalled and completely purged PostgreSQL from my laptop. I had to make sure that there was no trace of it left anywhere on my system. I had to kill the open ports, stop the services and then uninstall the program and all of its dependent packages. I reinstalled the database and ran the program. It worked! Now, I had to uninstall and purge again and start documenting. I think I did this about 5 times before being confident enough to submit a pull request. This was their response:
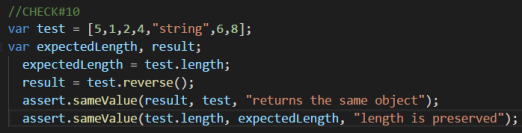
![Screenshot_2018-04-23 Download , Share and Delete buttons do not loose their highlight after each respective action is can[...]](https://jpham14.files.wordpress.com/2018/04/screenshot_2018-04-23-download-share-and-delete-buttons-do-not-loose-their-highlight-after-each-respective-action-is-can.png?w=739)
What was frustrating about all of this is that their README only says “Install PostgreSQL”. There are a bunch of additional steps you need to do before getting the server up and running and to get the extension to run on localhost. If there were instructions initially, this would have saved me a lot of time (and tears). I had hoped that with my contribution, I could have help somebody with the installation and with no troubles. I understand where they are coming from, but they should have at least linked PostgresSQL’s instructions some where on their page.
For my second bug fix, I found a CSS issue that causes buttons to remain active, even after being clicked. 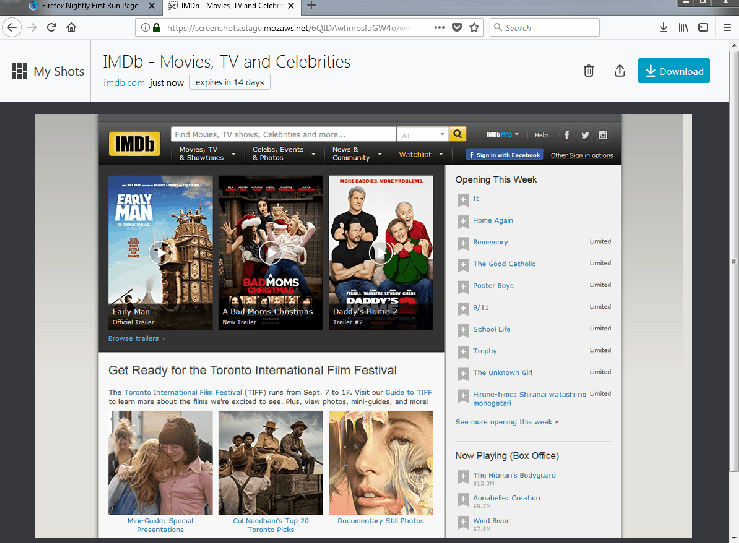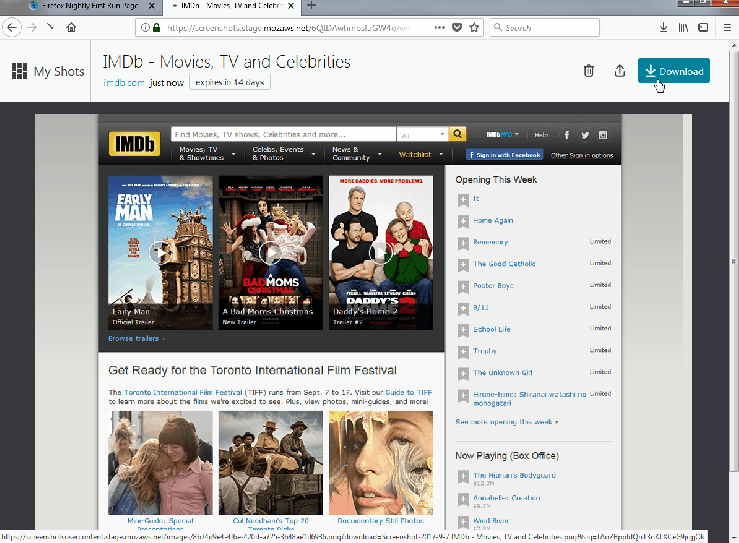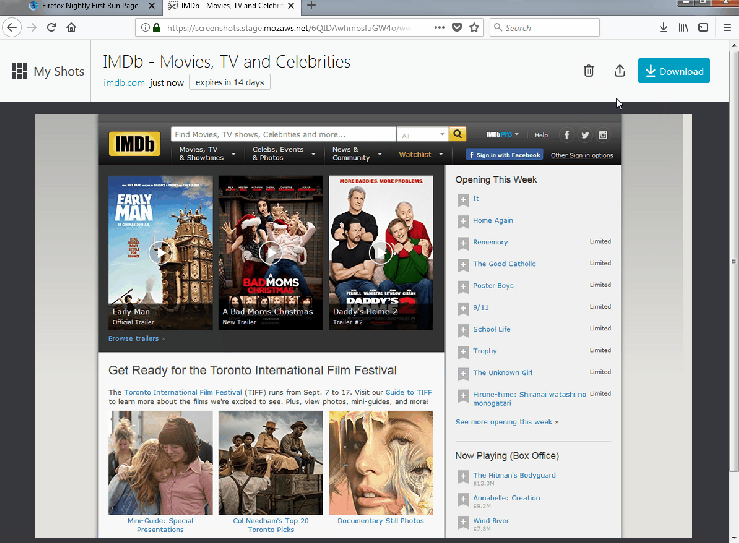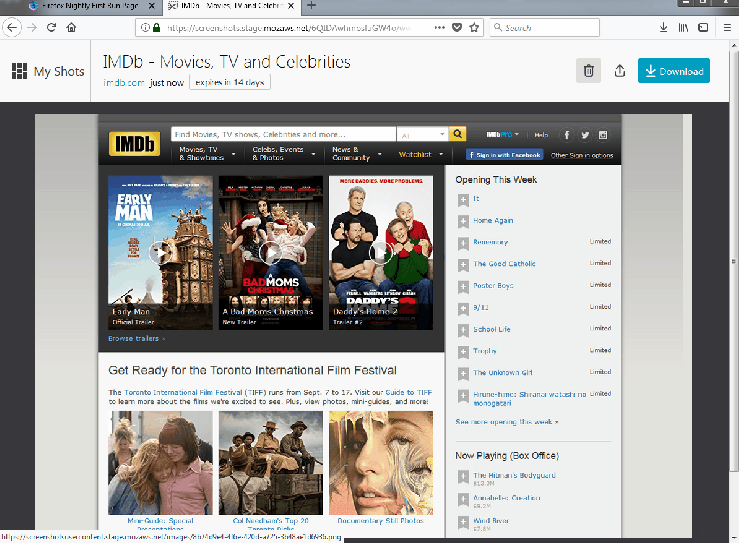
I found this bug quite simple to solve. Now that I am familiar with the code, I located the CSS file that contained the styling for the button. The issue was that the styling for hover and focus were the same. I separated the two attributes and removed the background-color for focus. I kept the border however, so that you can still distinguish if the button is in focus or not. I submitted the pull request with no issues this time and hopefully they accept my code change.
During the last 4 months, I gained first hand experience in the open source world. I was hesitant in the beginning, thinking that this would be to difficult for me. At some point, this was true, but I still tried my best with these assignments. For this last release, I felt like I learned how challenging yet rewarding open source projects can be. This was definitely a learning experience that I can carry forward throughout my career.