For stage 2, I chose to focus on the Chameleon algorithm in the Density program. The Chameleon algorithm is the fastest of the 3 algorithms Density provides. The source code did not contain many loops or complicated functions. I couldn’t find an area that was further vectorizable, so I focused my efforts on optimizing the compilation of the code. The compiler already uses the -Ofast flag to compile, so I wanted to fine-tune the optimization flags.
I started with the floating-point operation flags. Since we are solely focusing on speed, we can disregard rounding errors and inaccurate calculations. With this is mind, I tried to toggle any flags that corresponds with math calculations. This became quite tricky trying to toggling flags. I started with the flags listed below:
-fno-signed-zeros
-fno-trapping-math
-funsafe-loop-optimizations
-fno-signaling-nans
I was using a dummy file that was 25MB. I compiled and ran the program a few times to see if it those flags made a difference. I didn’t see a significant difference with these flags. I read on forums and websites that these flags should increase the speed of the program. I was confused why it wasn’t working for me. I started looking into what flags Ofast has enabled by default. What I learned is Ofast is just O3 with the ffast-math flag enabled. With ffast-math enabled, the flags listed above are enabled by default. Now, I had to look for other flags the toggle.
-fselective-scheduling
-fselective-scheduling2
-floop-interchange
-floop-nest-optimize
I logged the results and compared them with the initial run. I have highlighted the best runs for each additional flag. As we can see, the results do not vary much from the initial run. There were moments where I consistently had good results, but once I ran the initial settings again, the results remained the same.
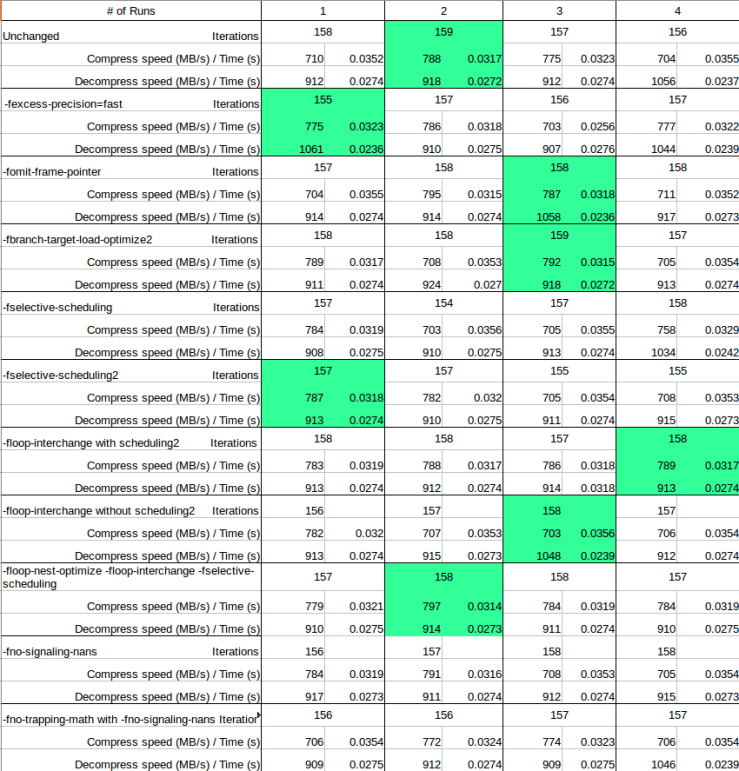
I believe that the additional optimization flags didn’t work because the logic of the code did not contain complicated loops or calculations. I wasn’t sure what to do at this point, as I have tried as much as I could. I had the idea to profile the program to see if there were any hotspots within the code. I tried profiling the code during stage 1 but I couldn’t run gprof because when I compiled the code, it did not generate a gmon.out file. Their Makefile was a bit too complex for my understand so I didn’t want to alter anything within it. What I did instead was download Intel Vtune Amplifier which is a Graphical profiler from Intel.
I was able to pinpoint where the most amount of time was spent within the code. There were 2 hotspots found, during the functions density_compress_with_context and density_decompress_with_context. 
The compress function takes about 1 second longer than the decompression. I stepped into the function where we can see exactly what is happening within the assembly code. Below shows the hotspot within the compression function. The function takes some time moving and comparing as seen with movl, xorl and test.

Again, we see that in the decompress function, the moving of values in the registers takes up the most amount of time.

At this point, I am not sure how else I can optimize this code. I found a few comparisons between Density and other compression/decompression software. For the majority of the comparisons, Density algorithms were the fastest.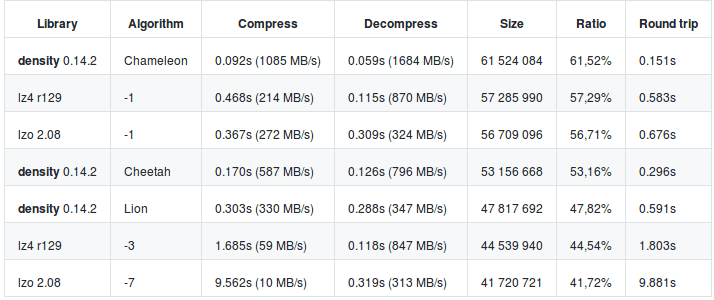
On this site that shows benchmarks of different compression and decompression software, Density still has one of the fastest speeds. Density’s compression ratio however, is on the lower end. This chart that shows the Compression Speed VS Decompression speed, Density is quite superior compared to the other softwares.
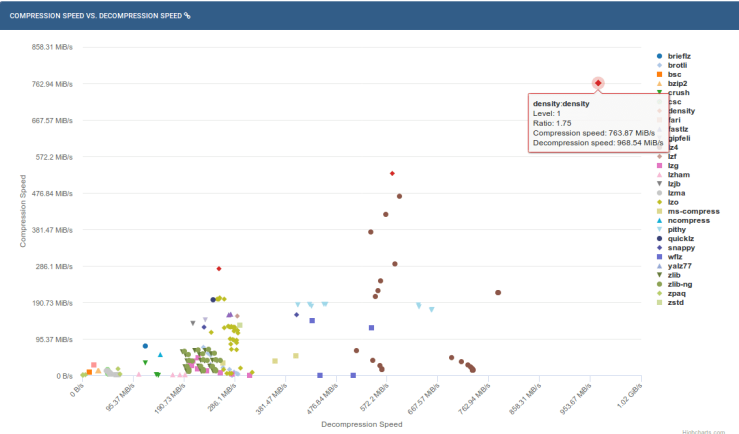
In conclusion, Density’s compression and decompression algorithms is quite efficient as it is. Their code logic and compiler optimization is refined and there isn’t much more I could do. I have attempted to modify compiler flags which yielded no significant changes and I’ve tried to restructure and modify the code, but to no avail. Perhaps in the future, I should take a look at their other algorithms to see if I can some how find a way to optimize that.
